
Imagine that you’ve undergone some kind of education – courses, university, training – whatever.
In any case, you’ve obtained the essential knowledge you plan to apply in real life.
You invested your time and money, got a particular understanding of some niche, and …
Stayed unnoticed out there for some reason, with all your wisdom and unemployed.
Unfortunately, this often happens with ML models – 54% don’t go for production, as reports say.
So, the bigger problem here is not to train a model – but to deploy it into the production workflow.
And here comes MLOps – an evolving discipline that combines the best practices from software engineering, data science, and DevOps to streamline the deployment and management of ML models in production. It serves as a bridge between ML research and the reality of deploying ML models at scale.
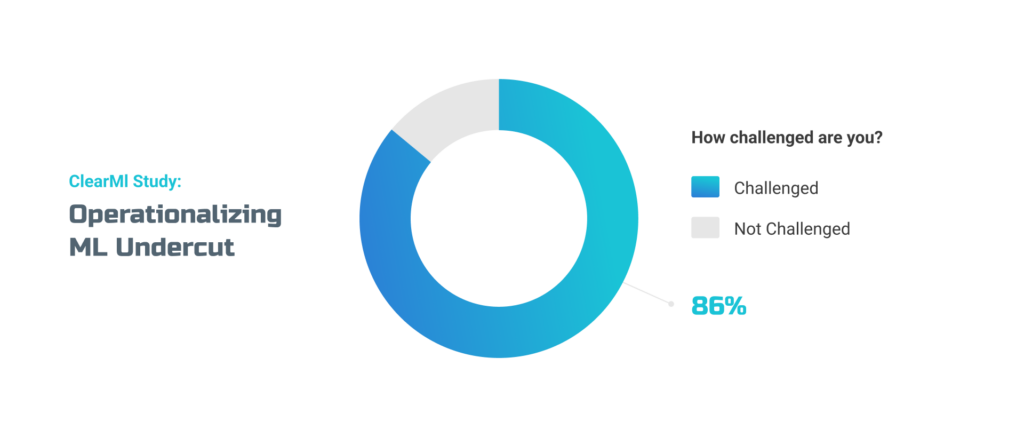
Still, the problem needs to be solved. According to a recent survey among 200 U.S.- based machine learning decision-makers, most respondents agree they fail to use ML to generate business and commercial value due to the difficulties of implementing it on a large scale.
In this article, we’ll tap a toe into the world of MLOps and shed light on its significance for organizations looking to harness the full potential of ML. We’ll explore the critical components of MLOps, its benefits to businesses, and practical steps for integrating MLOps into existing workflows.
What is MLOps and Why Is It Important?
So, what is MLOps in general?
MLOps is a set of practices and methodologies that aim to streamline and operationalize machine learning models’ development, deployment, and maintenance in production environments. It combines machine learning, software engineering, and DevOps principles to ensure ML systems’ reliable and efficient operation.
So, why is MLOps for you? Due to its enrooted characteristics, the concept bears several advantages your business might leverage.
- Efficiency and Scalability: MLOps enables businesses to streamline and automate the entire lifecycle of machine learning models, from development to deployment and maintenance. This automation improves efficiency by reducing manual efforts, ensuring consistency, and eliminating human errors. It also allows for scalable model deployment, enabling businesses to handle larger workloads and adapt to changing demands without compromising performance.
- Reliability and Performance: The approach emphasizes monitoring, tracking, and managing the performance of machine learning models in production. By implementing robust monitoring and alerting systems, businesses can detect issues and anomalies in real-time, ensuring the reliability of their models. MLOps practices also facilitate continuous improvement by enabling regular model retraining and updates, which helps businesses maintain high performance and accuracy over time.
- Collaboration and Communication: This concept promotes collaboration between data scientists, engineers, and operations teams. By establishing a shared set of tools, practices, and workflows, MLOps facilitates effective communication and coordination, leading to better stakeholder collaboration. This enhances the integration of machine learning into business processes, enables faster decision-making, and fosters a data-driven culture within the organization.
MLOps vs. DevOps vs. LLMOps: What’s the Difference?
You may think that MLOps is somehow similar to DevOps. At the same time, there’s a noticeable trend toward LLMs (Large Language Models) usage. The misunderstanding of these concepts may create some confusion. So let’s figure this out.
MLOps specifically addresses the challenges of managing machine learning models in production. It emphasizes automation, collaboration, monitoring, and version control to ensure ML systems’ reliability and efficiency. Also, it incorporates model governance, compliance, and model retraining. MLOps is tailored to the unique requirements of machine learning projects and the continuous improvement of ML models.
DevOps, on the other hand, is a broader approach that focuses on the collaboration and integration between software development and IT operations teams. It aims to optimize the development and deployment of software applications through automation, continuous integration, and continuous deployment practices. DevOps emphasizes the seamless coordination between different teams involved in the software development lifecycle, enabling faster and more reliable software delivery.
LLM Ops refers to the specialized operations and practices for managing large language models, such as OpenAI’s ChatGPT, Alpaca, and others. It focuses on handling the unique requirements and considerations specific to deploying and maintaining these large language models in production environments. The approach may involve infrastructure management, resource allocation, fine-tuning models, monitoring for bias or ethical concerns, and ensuring compliance with regulations and guidelines. LLM Ops is an extension of MLOps tailored to large language models’ specific characteristics and challenges.

Now, let’s sum it up simply:
- MLOps is a domain-specific practice that addresses the operational challenges of managing machine learning models in production.
- DevOps is a broader approach focusing on the collaboration and integration of software development and operations.
- LLM Ops is a specialized area within MLOps that deals with the unique considerations related to large language models.
The MLOps pipeline
So, how does MLOps work?

As with any complex process, it has several stages and deliverables. These MLOps stages together form a comprehensive MLOps pipeline that enables organizations to effectively manage, deploy, and maintain machine learning models in production environments. Each stage delivers its output, contributing to the machine learning systems’ efficiency, scalability, and reliability.
- Data Acquisition and Preparation. In this stage, data is collected from various sources and prepared for model training. This involves data cleaning, handling missing values, encoding categorical variables, feature engineering, and splitting the data into training and testing sets.
Deliverables: Cleaned and preprocessed dataset, engineered features, train-test splits, and data transformation pipelines.
- Model Development and Training: This stage involves developing machine learning models using the prepared data. Data scientists experiment with different algorithms, architectures, and hyperparameters to build models that best address the problem to solve. The models are taught on the training dataset, and various evaluation metrics are used to assess their performance.
Deliverables: Trained machine learning model(s) that have undergone optimization and tuning
- Model Packaging. Once the models are trained, they need to be packaged for deployment. This stage involves saving the trained model parameters, architecture, and other necessary files or dependencies into a deployable format. The packaged model may include model files, configuration files, pre-processing steps, and any additional resources required for deployment.
Deliverables: Packaged model artifacts, such as serialized models, model configuration files, and associated dependencies.
- Model Deployment. Here, the packaged models are deployed to production environments, making them accessible for inference or predictions. This stage involves configuring the deployment environment and setting up the necessary infrastructure, such as servers or cloud-based services. The models are integrated into the target system, often exposed through APIs or other interfaces to receive input data and produce predictions.
Deliverables: Deployed machine learning model(s) in a production environment, typically accessible via APIs or other interfaces.
- Model Monitoring and Performance Tracking. Once the models are deployed, monitoring their performance and behavior in real-time is crucial. This stage involves setting up monitoring systems to track metrics, such as prediction accuracy, response times, or resource utilization. Any anomalies or issues are detected through monitoring, allowing for timely interventions and improvements.
Deliverables: Real-time monitoring metrics, logs, and alerts to track the performance and behavior of deployed models.
- Model Maintenance and Retraining. Models require ongoing maintenance to remain accurate and relevant. This stage involves periodically retraining the models using new data or user feedback. Model performance is evaluated, and new training cycles are initiated to update the models if necessary. Maintenance may also include addressing data drift, concept drift, or changing business requirements.
Deliverables: Updated and retrained models, incorporating new data or feedback to improve model accuracy and relevance.
- Continuous Integration and Continuous Deployment (CI/CD). CI/CD principles are applied to automate the deployment and updates of machine learning models. This stage involves setting up CI/CD pipelines that automate the building, testing, and deployment of models whenever updates are made. It enables a seamless and efficient process for delivering new versions of models into production while ensuring consistency and reliability.
Deliverables: Automated CI/CD pipelines that enable efficient and reliable model deployment and updates.
- Governance and Compliance. The final stage focuses on ensuring ethical and regulatory compliance using machine learning models. It involves documenting model behavior, tracking model usage, performing audits, and adhering to legal and ethical guidelines. Here, transparency, fairness in model decision-making, data privacy, and security considerations are addressed.
Deliverables: Documentation, model explainability reports, compliance audits, and adherence to regulatory and ethical guidelines.

A Few Signs that You Need MLOps
Businesses usually need MLOps when actively deploying and maintaining machine learning models in their production environments. MLOps becomes essential to address challenges as machine learning initiatives move from experimental or research phases to real-world applications.
Here are some key factors that suggest businesses should consider adopting MLOps:
- Real-Time or quick model deployment: If the business requires real-time or near-real-time predictions, MLOps can ensure smooth and efficient model deployment, monitoring, and updates, allowing the organization to respond quickly to changing business needs.
- The complexity of machine learning projects: When businesses have multiple machine learning projects running simultaneously or dealing with large, complex models and datasets, MLOps can provide the necessary structure and automation to manage and coordinate these projects effectively.
- Need for reliable model performance: When accurate and reliable model predictions are crucial to the business’s success, MLOps helps maintain model quality, ensures ongoing monitoring, and facilitates model retraining to keep models up-to-date.
- Scalability and stability: As the organization’s machine learning initiatives grow, MLOps allows for the scalable and stable deployment of models, enabling the business to handle increased workloads and ensure consistent model performance.
- Efficient Resource Management: When businesses want to optimize the utilization of computational resources and reduce operational costs associated with machine learning, MLOps streamlines processes, automates workflows, and enhances resource allocation.
- CI/CD. Managing the updates can be challenging if a company frequently updates and deploys new versions of machine learning models. MLOps enables the integration of CI/CD principles into the machine learning workflow, automating the build, test, and deployment processes.
- Automation of ML Pipeline: When a business regularly trains and deploys machine learning models, manual processes for data preprocessing, model training, and deployment can become time-consuming and difficult to scale. MLOps provides automation capabilities that streamline the entire ML pipeline, from data acquisition and preparation to model deployment and maintenance.
How to Make It Work?
Integrating MLOps is an iterative process that may require adjustments based on your company’s needs and challenges.
However, it usually takes several following steps:
- Assess Current State and Define Goals. Evaluate your existing ML workflow and identify pain points, inefficiencies, and areas for improvement. Define clear goals and objectives for integrating MLOps, such as improving efficiency, reducing deployment time, or enhancing model monitoring. Understand your company’s precise needs and requirements to tailor the MLOps implementation accordingly.
- Establish Collaboration and Communication. Foster collaboration and communication between different teams involved in ML projects, including data scientists, engineers, and operations. Encourage regular meetings, knowledge sharing, and cross-functional discussions. Establish a common understanding of MLOps principles and workflows to ensure smooth coordination throughout the ML lifecycle.
- Implement Automation and Version Control. Introduce automation tools and practices to streamline the ML pipeline. Use tools for data preprocessing, model training, and deployment to reduce manual efforts and increase efficiency. Implement version control systems to track changes in code, data, and models, ensuring reproducibility and facilitating collaboration.
- Set Up Monitoring and Performance Tracking. Establish robust monitoring systems to track deployed ML models’ real-time performance, behavior, and integrity. Define key metrics, such as accuracy, latency, or resource utilization, and set up monitoring tools or dashboards to track these metrics. Implement alerting mechanisms to detect anomalies and issues promptly.
- Continuous Integration and Deployment (CI/CD). Integrate CI/CD principles into the ML workflow to automate the build, test, and deployment processes. Establish CI/CD pipelines that enable efficient and reliable model updates and deployments. Implement automated testing frameworks to validate model changes before deployment, ensuring quality control and minimizing risks.
We at UnidataLab are ready to support you at any of these stages, as we have proven expertise in training and deploying models on different platforms and workflows.
Have you got any ideas? Let us know, and we’ll discuss it!



