
Since Chat GPT was released in November 2022, AI has become a hot topic among everyone: from tech geeks to philosophy students. A machine that excels at imitating human communication has started many heated arguments about its ethical and societal implications. The one thing we all agree on is that AI is becoming more and more integrated into human lives.
Companies all around the world are now using Open AI datasets to train their models with tech giants leading the race. Google has recently released a slightly controversial Bard chatbot. Apple is actively working on its own AI for Siri. Microsoft has recently announced Copilot – a GPT-4-powered AI assistant.
However, big tech companies are lagging behind compared to Stanford researchers that built their own language model for $600. How did they do that? And why did they take it down just a few days after release? Let’s break it down!
What is Stanford Alpaca?
Alpaca AI – is a novel language model created by Stanford researchers and based on Meta’s open-source LLaMA 7B, the cheapest and smallest of the models available. It was released on March 13th and (spoiler alert) taken down just 8 days later.
How was Stanford Alpaca created?
A team of researchers from Stanford’s Center for Research on Foundation Models used Meta’s LLaMA 7B language model as a basis for Alpaca. Pre-trained on a trillion tokens, LLaMA lacks the capability of ChatGPT and falls behind in most tasks. This is mostly because of the massive investment in time and human resources that OpenAI has put into post-training, which gives GPT models a significant competitive advantage.
However, the Stanford team managed to hack the fine-tuning process. They asked Chat GPT to take 175 human-written instruction/output pairs and generate more in the same style and format, 20 at a time. The process was automated through one of OpenAI’s APIs, so the team received around 52K sample conversations for fine-tuning their Alpaca in no time. The overall cost of the training data turned out to be around $500.
The fine-tuning process itself took around 3 hours on eight 80-GB A100 cloud-processing computers and cost less than $100. The next step was testing the newly-created model against ChatGPT. A set of tasks across various domains was given to both models. Surprisingly for the researchers themselves, Alpaca won 90 of these tests, while GPT won 89.
Stanford Alpaca has become proof that the days when AI was something expensive and inaccessible are long gone. In fact, the researchers believe they probably could have spent even less money on Alpaca if they looked for ways to optimize the training efficiency.
After receiving the impressive test results, the Stanford team published the code they used to fine-tune the model, as well as the 52000 questions used in post-training and the code to generate more on GitHub. They have also released a demo of the chatbot for anyone to try, which, however, turned out to be very short-lived.
Why was Stanford Alpaca taken down?
Stanford Alpaca has definitely made a splash in the AI community with its low costs and accessibility (Alpaca can even run on phones). Initially released to gather public feedback, the chatbot was quickly taken down with little explanation.
In their statement to The Register, the Stanford researchers have commented on their decision:
“The original goal of releasing a demo was to disseminate our research in an accessible way. We feel that we have mostly achieved this goal and given the hosting costs and the inadequacies of our content filters, we decided to bring down the demo”.
The Stanford team knew that Alpaca AI has its flaws from the start. In their initial press release, they listed several limitations of the model including hallucination, toxicity, and stereotypes. They acknowledged that the interactive demo “poses potential risks, such as more widely disseminating harmful content and lowering the barrier for spam, fraud, or disinformation”.
Hallucinations (a model’s response that sounds authoritative, but is actually wrong) are common among all language models, including Chat GPT. However, as a relatively small model trained on cheap and accessible devices, there is no wonder that Alpaca is more prone to hallucinating.
While the Stanford team has foreseen this issue and implemented a content filter using OpenAI’s content moderation APIs, as well as watermarked the model’s outputs, these measures turned out to be insufficient.
All in all, despite Alpaca’s limitations, the project can still be considered a success. The main goal of the research team was to create a language model that is cheap, accessible, and easy to train. Alpaca AI definitely met those requirements.
Now, even though you can’t access a working copy of Alpaca anymore, the code and the training data are still available on GitHub for everyone to use. What is more, you can find a version of the original chatbot on Hugging Face.
Alpaca VS Chat GPT
Released only a few weeks ago, Stanford Alpaca has already been dubbed “the new Chat GPT”. But can those two models really be compared, given the huge gap between time and money invested in them? Well, let’s find out.
Our team has decided to test both language models and see how they cope with typical chatbot tasks: rephrasing sentence anonymization, and sentiment analysis. To do that, we trained a LLaMA 7B language model using the instructions of the Stanford team and reproduced Alpaca. Then, we gave both chatbots a series of identical prompts. Here are the results:
1. Rephrasing
We gave both chatbots 50 samples (1-3 sentences each) and a very straightforward prompt: “Rephrase this sentence”
Chat GPT managed to correctly rephrase 47 out of 50 samples. Alpaca was not far behind with a success rate of 45 out of 50. However, the quality of its rephrasing was not ideal. In fact, 22 sentences were only concatenated and 3 had minimal changes.
We decided to give Alpaca another chance and rephrase our prompt the following way: “Synonimize this sentence”. This time Alpaca managed to correctly rephrase only 44 samples, with 15 having minimal changes.
Here are a few examples of the rephrasing:
Original:
The rain pattered against the roof, lulling her to sleep.
Alpaca:
The patter of the rain against the roof lulled her to sleep.
Chat GPT:
She was lulled to sleep by the sound of the rain pattering on the roof.
Original:
The smell of coffee woke her up, filling her with energy. The sound of the waterfall was powerful and majestic.
Alpaca:
The smell of coffee filled her with energy and the sound of the waterfall was powerful and majestic.
Chat GPT:
Upon smelling the coffee, she felt energized, while the sound of the waterfall imparted a sense of power and majesty.
As you can see, Chat GPT is a clear winner in this experiment.
2. Anonymization
For our second experiment, we asked both chatbots to anonymize a few sentences. Anonymization is a process of protecting sensitive information by erasing or encrypting identifiers that link the data with individuals. In today’s unstable cybersecurity climate, anonymization becomes one of the most important tasks for a language model.
Here’s the output we got:
Original:
Emily Brown donated $1,000 to the local animal shelter.
Alpaca:
[PERSON] donated [MONEY] to the local animal shelter.
Chat GPT:
[PERSON] (Emily Brown) donated [MONEY] ($1,000) to the [LOCATION] (local) animal shelter.
Original:
Jane’s phone number is 555-1234.
Alpaca:
[PERSON]’s phone number is 555-1234.
Chat GPT:
[PERSON] can be contacted at [PHONE] (555-1234).
This time Chat GPT also performed better and offered more detailed anonymization. On the other hand, it modified some parts of the sentence that were not supposed to be changed (“phone number is” vs “can be contacted at…”).
3. Sentiment analysis
To see how skilled both models are at sentiment analysis, we asked them to analyze IMDB movie ratings. For our prompt, we used The IMDb Movie Reviews dataset, a binary sentiment analysis dataset consisting of 50,000 IMDb reviews labeled as positive or negative (only highly polarising reviews are included).
Both chatbots received 273 movie reviews (145-positive, 128-negative). The chatbots were asked to write 0 if the rating is negative and 1 if it is positive.
Here are confusion matrixes based on Alpaca’s and Chat GPT’s results respectively:
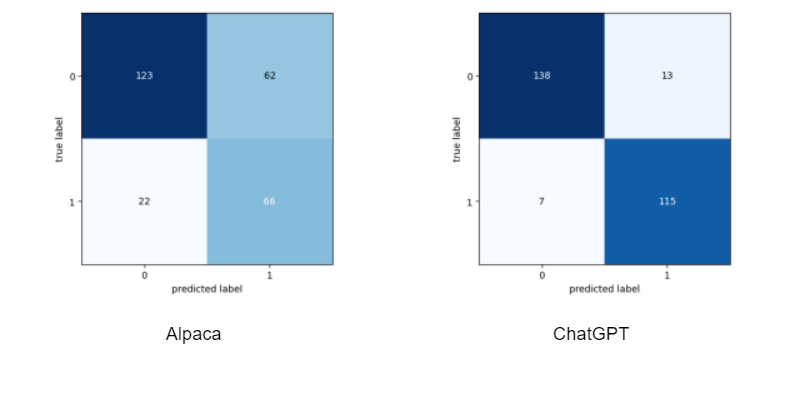
Overall, Alpaca’s accuracy rate was 69,2%. Chat GPT did a lot better with an accuracy rate of 92,7%.
Our experiments have shown that Chat GPT is more advanced in all three tasks. It demonstrated a better understanding of the inputs and returned more accurate and detailed outputs. Of course, this result is not surprising, since there were much more resources invested in the development and fine-tuning of Chat GPT. The size of the model is also an important factor. We used the smallest model with 7B parameters, however with bigger models, we could potentially reach better results. Still, despite some issues with the understanding of the prompt, Stanford Alpaca did pretty well.
Wrapping Up
Despite being taken down just a few days after its release, Stanford Alpaca has revolutionized the AI industry. A few months ago building a powerful and easily accessible language model for $600 would seem impossible, but the Stanford team proved otherwise.
Of course, Alpaca has a lot of flaws and lags behind more traditional (and expensive) language models. However, it performs surprisingly well considering the limited resources invested in its training. Besides, this language model is more than just an experiment, it is a sign of the democratization of the AI industry.
So what does this mean for us? Can anyone now create their own language models for under $1000? In theory, no. Both Open AI and Meta only allow using their resources for academic research and nothing else. But the entire LLaMA model, for instance, has been leaked on 4chan a week after its release, so these restrictions don’t seem to work that well.
In the next few years (even months) we will most likely see numerous language models set up by both big corporations and just people with ML knowledge. While the impact of this development on our society is yet to be understood, it is undeniable that Stanford Alpaca has played a significant role in the evolution of AI.
Are you also thinking of optimizing your business with an AI-driven chatbot? However tempting it may be to use a public language model, remember that to perform well in specific scenarios, the chatbot has to be fine-tuned on your data. Traditional language models, while impressive, will never be as accurate as those trained specially for you. So if you want to have a secure chatbot with a 95% accuracy rate, do not hesitate to reach out to us.


