
AI-powered pronunciation scoring for online education platform
In computer-assisted language learning systems, one of the tasks involved is pronunciation scoring which aims to automatically detect pronunciation problems, allowing the system to provide valuable feedback to the student. Pronunciation scoring systems give, for an utterance or set of utterances, a score saying weather the pronunciation was correct. Usually, the customers of such projects are online schools of foreign languages. With the help of pronunciation scoring, you can evaluate how well the user pronounced this or that phrase. But here we will focus on the case where the user has to reproduce the suggested phrase. The purpose of pronunciation scoring is to assess whether the user pronounces all phonemes in a word correctly. In addition, such services can indicate problem areas. That is, to evaluate the pronunciation of each sound and if an error has occurred, it will give a hint to eliminate such an error.
Our client was an online educational platform. They wanted to add some interactivity to their platform and therefore came to us to work on this innovation. Moreover, they don't provide only one language but try to cover as many popular languages as possible and currently support 80+ foreign languages. They already have the entire pipeline built and currently provide user training. This became especially relevant with the beginning of the quarantine. Since face-to-face assignments are no longer in demand or are impossible the customer base is growing rapidly. Out client received additional funding, which they decided to invest on the development of their product, namely this interactive part.
Solution
A micro-service was created in a way that it has its own API interface and allows the client system to evaluate the user's pronunciation.
How it works
The pronunciation scoring service supports a cross-language architecture and does not rely/is not dependent on the language in use (English, German, etc.). IPA (International Phonetic Alphabet) combined with ASR (Automatic speech recognition) provides this support. IPA phonemes describe the transcription independently of the language or phrase. Since the service works only with phonemes, it doesn’t matter in which language the phrase is voiced. ASR model is used for audio file segmentation and phonemes recognition. Thus, the output of the ASR model is a set of phonemes with intervals in the time during which the user pronounced them. The spoken phrase evaluation service includes a model that converts a set of phonemes into linguistic vectors. This model is applied to the phonemes of the ground-truth phrase and the phonemes pronounced by the user. Linguistic vectors describe each phoneme according to certain attributes (vowel, consonant, fricative, nasal, etc.). Each set of phonemes is converted into a matrix of numbers. The service compares the user’s matrix with the ground-truth matrix using the DTW (Dynamic Time Warping) algorithm, which produces an overall score of the spoken phrase. In addition to the overall score of the phrase, the service also returns a score for each phoneme. This is used by the client to emphasize to the user the part of the phrase that is pronounced incorrectly. The phoneme estimation algorithm based on linguistic vectors makes the evaluation of the user’s pronunciation more accurate and flexible than a direct comparison of recognized phonemes.
The user utters a certain phrase, which is recorded and transmitted to the service in the form of audio.
The service pre-processes the received audio to improve the signal (de-noising, audio enhancement).
The processed audio is transmitted to the ASR model that returns a list of IPA phonemes and their corresponding time intervals.
The service also receives the correct set of IPA phonemes (ground truth transcription) which will be used for comparison with the phonemes pronounced by the user.
Both sets of phonemes are converted into linguistic features, which describe are grouped into two vector matrices (ground truth and user).
In the next stage, these matrices are compared by the evaluation algorithm based on the similarity score. The evaluation algorithm returns an overall score of the pronounced phrase and detailed scores for each phoneme.
The pronunciation evaluation service returns the time interval for each pronounced phoneme, its pronunciation score, and the overall score of the whole phrase.
The client processes this information and presents it to the user as an overall score of the pronounced phrase and highlights the phoneme scores in different colors.
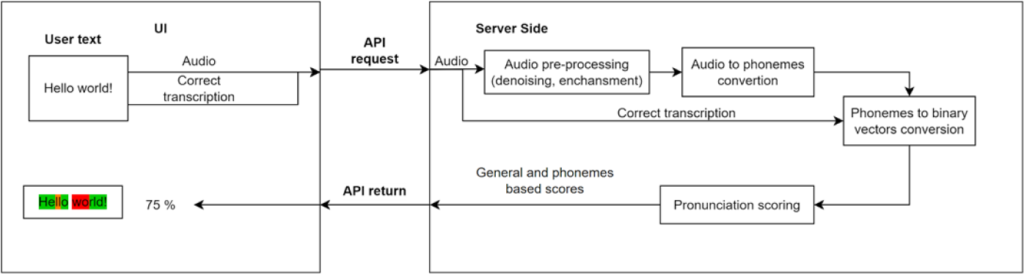
Pronunciation evaluation block diagram
Our challenges:
Linguistic features
The linguistic approach was developed and applied to evaluate the quality of phoneme pronunciation. Initially, an evaluation based on the comparison of the phonemes themselves was used. However, this evaluation was insufficient in the case of close phonemes (for example, the difference between fan and van is a phonetic difference in voicing). In this case, the system evaluates such pronunciation as absolutely incorrect. Therefore, the team decided to do an evaluation based on linguistic attributes. Such attributes provide a deeper assessment of each phoneme and therefore allow a more flexible and accurate evaluation of the pronounced phrase.
Phonemes segmentations and scoring
According to the client’s requirements, the pronunciation evaluation service, in addition to the overall phrase score, should return the time interval and score for each pronounced phoneme. Since the service built based on the DTW did not allow this and only provided an overall score of the phrase, the AI team decided to develop an algorithm based on DTW that could additionally evaluate each phoneme separately. In this way, the algorithm returns detailed feedback that satisfies the client and improves the quality of the user experience.
Cross-language architecture
Since the client’s product supports about 80 languages, it was necessary to develop a language-independent scoring algorithm. This is due to the fact that it was necessary to limit the number of models that our system will use and simplify support for new languages in the future. Therefore, we decided to evaluate not the words/phrases themselves, but their transcriptions. To do this, we used the IPA transcription, which allows us to describe the phonemes of a large number of languages and further evaluate the pronunciation based on the transcription (list of phonemes), not on the text.
Audio quality
After integrating the pronunciation evaluation service with the client platform, we provided users with access to the service for testing. We noticed that the service received quite noisy and low-quality audio samples, which affected the accuracy of the pronunciation evaluation.
Therefore, we decided to apply VAD (voice activity detection) to cut out the necessary pieces and de-noise the audio. It was also agreed to apply audio pre-processing by signal enhancement algorithms since the users’ equipment is not always of high quality.
Project stages
Our team held a series of refinement meetings with the client to describe the problem, what they expected from the solution and how it should work. At this stage, the API contract and further steps for the implementation of this project were agreed.
Our team conducted a number of studies to adapt Automatic speech recognition (ASR) to solve the client’s problem. Also, within the scope of this study, it was agreed how to perform pronunciation scoring, namely, to convert the text into a list of phonemes. After that, convert the phonemes into linguistic vectors and compare the matrices built based on these vectors.
At this stage, our team developed a pronunciation evaluation service with an API according to the client’s requirements. The service accepts the user’s sound, processes it using internal algorithms, and returns detailed feedback on the phrase and phoneme level to highlight incorrectly pronounced places on the UI.
The source code was delivered to the client via a private repository on GitHub with detailed documentation on deployment and use of the service. In addition, a project summary was prepared, which describes in detail each stage of project development, including research and a final summary.
After a definite time interval of the client’s use of our service, our team collected user-generated feedback. Based on this information, certain improvements have been implemented, which include improving the input audio and the accuracy of pronunciation estimation.