
Imagine that somehow you’ve managed to obtain the Tree of Knowledge. It will give you the wisdom, prosperity, and good fortune you’ve always wanted.
Would you protect it or allow anyone interested to touch it?
I think the answer is obvious.
In today’s data-driven world, integrating Machine Learning Operations (MLOps) has enabled organizations to unlock the power of trained models.
And this trend will only gather momentum: IDC’s report predicts that 60% of enterprises will implement MLOps/ModelOps capabilities, operationalizing their machine learning workflows by 2024.
However, with the growing reliance on machine learning models comes an urgency to prioritize MLOps security.
In 2022, the vulnerabilities and risks associated with MLOps security became increasingly evident. According to Veracode’s report, about 70 percent of applications indicate at least one security flaw by the time they have been in production for five years.

These breaches may negatively affect data integrity, customer trust, and regulatory compliance, not to mention financial losses.
This article explores the significance of MLOps security and highlights its critical features. Also, we’ll share some insights from Unidatalab’s experience.
MLOps Security and Facts to Consider
First things first. What is MLOps security in general?
MLOps security refers to security measures to protect machine learning operations (MLOps) systems. These systems are vital in managing the lifecycle of machine learning models and are essential to the success of many businesses.
Ensuring security in MLOps involves implementing security protocols and best practices to provide the integrity, confidentiality, and availability of the system and its data.
There are several reasons why companies should take it as a vital part of their operations and processes.
- It can bring efficiency to a company by allowing data scientists to focus on their tasks more and achieve faster development and deployment of their machine-learning models.
- MLOps systems can unintentionally leak sensitive information.
- The infrastructure for building and deploying machine learning models can be vulnerable to attacks.
- Any ML-empowered business must ensure its systems and resources comply with relevant laws and regulations.
Generally speaking, by prioritizing MLOps security, businesses can protect their assets and maintain the trust of their customers.
Building and Maintaining MLOps security with Unidatalab
Telling you about MLOps security, we couldn’t help but share our live expertise with you. And for that purpose, we invited our ML engineer, Vitalii Brydinskyi. He will share some insights from this field.
Vitalii, please introduce yourself and tell us a few words about your background.
Hello there! I’m Vitalii, and I am an ML engineer at Unidatalab. I got my master’s in Information and Measurement Technologies at Lviv Polytechnic National University and Electrical Engineering and Information Technology at Ilmenau Technical University (Germany). Currently, I am pursuing my Ph.D. at Lviv Polytechnic National University.
How did your journey at Unidatalab start?
I joined Unidatalab around April 2020 when Yuri, our company’s CEO, offered me an opportunity to work on a compelling project. Actually, I’ve known Yuri since our university days. Shortly speaking, he significantly contributed to my machine-learning skills.
What’s your engagement here?
At Unidatalab, my main focus lies in tasks and research on speech recognition using artificial neural networks and machine learning. However, I’m also involved in other projects where I participate in research and development alongside my core area of expertise.
Sounds exciting and serious at the same time. Could you share something related to your current projects at UnidataLab?
Just recently, we’ve rolled out one. It was a promising fintech startup about to launch a recommendation system for personalized investment advice. At the final testing and preparation stage, they noticed that the recommendation system experienced hallucinations, generating inaccurate user suggestions. Worried about their customers and reputation, they approached Unidatalab.
Oh, that’s a real trouble. Could you tell our readers a couple of words about hallucination? What is that, and what’s the effect if not addressing it properly?
Generally, hallucination is the model condition where it generates inaccurate or false outputs.
For example, a user with a conservative risk profile and a long-term investment goal may receive a recommendation to invest a significant portion of their portfolio in high-risk, speculative assets. This recommendation would be a hallucination because it deviates from the system’s intended purpose of providing personalized and suitable investment advice.
Such cases are a significant issue for businesses because they can lead to unreliable recommendations or predictions, potentially impacting user trust and the overall effectiveness of AI systems.
Ah, now I see what the consequences could have been. Very intriguing. Please go on.
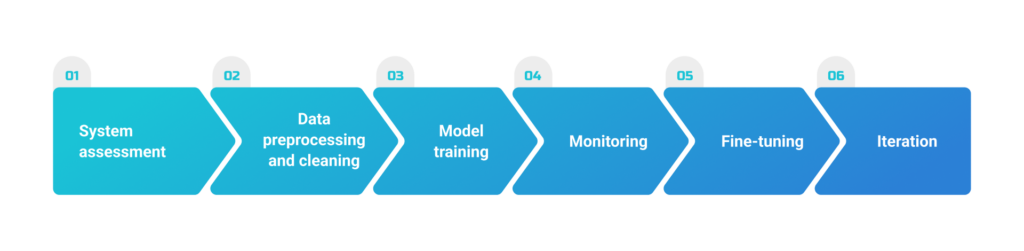
We started with a thorough assessment. The team carefully analyzed the recommendation system’s architecture, data pipelines, and model training processes. Through this stage, we identified potential sources of the hallucination issue, such as flawed model configurations.
Then, Unidatalab focused on data preprocessing and cleaning. The ML team developed custom data validation scripts to detect and remove anomalies, ensuring that only high-quality enters the system. This step significantly reduced the chances of further hallucinations caused by inaccurate inputs.
And what was next?
Moving on to the model training stage, our engineers implemented particular procedures to address biases and improve model accuracy. They applied TensorFlow and PyTorch frameworks to fine-tune the existing recommendation models. By integrating additional regularization approaches and diverse data augmentation methods, our team enhanced the model’s generalization capabilities and reduced hallucination tendencies.
To ensure ongoing monitoring and prevention of future issues, UnidataLab integrated comprehensive testing and monitoring frameworks. We implemented anomaly detection algorithms and real-time monitoring systems to flag any unusual behavior in the recommendation system.
So, do you think the project was successful?
Overall, our efforts resulted in a significantly improved recommendation system capable of delivering accurate and reliable investment advice to future customers.
However, our ML team and their in-house team still collaborate on a regular auditing process to assess the model’s performance and make necessary refinements.
Would you describe hallucination as a common issue of MLOps security?
Unfortunately, it’s a challenge that many companies face when deploying AI solutions.
Hallucination mostly belongs to maintaining performance and credibility. It’s a concern within the broader domain of machine learning. It usually appears in complex models, when dealing with limited or biased training data, or due to other factors affecting the accuracy and reliability of machine learning systems.
For sure, addressing hallucination is critical to ensure the trustworthiness and effectiveness of MLOps deployments.
Then could you outline some current challenges, particularly for MLOps? And are there any at all?
Of course, there’s always something to overcome, especially in such a relatively young field.
First of all, maintaining the performance and reliability of machine learning models in production remains a constant challenge. Models may experience performance degradation over time or encounter concept drift. To overcome it, companies can implement robust model monitoring systems, continuously collect and analyze feedback data, employ techniques like A/B testing for model comparison, and adopt retraining strategies that ensure models stay up-to-date with changing data distributions and user requirements.
Also, MLOps often involves handling large-scale datasets and computationally intensive processes, requiring robust infrastructure and efficient resource management. Businesses can use cloud computing platforms for scalable and elastic infrastructure to tackle this challenge, employ containerization technologies like Docker for consistent deployments, and adopt orchestration frameworks like Kubernetes for automated scaling and efficient resource allocation.
And last but not the least. Which is ensuring compliance with regulations and privacy requirements (such as GDPR and HIPAA). This is critical due to the sensitive nature of the data involved and the potential ethical implications. To address this challenge, companies can implement strict data governance policies, perform regular audits and assessments, and establish clear data handling and model deployment guidelines to ensure adherence to regulatory frameworks.
Thanks a lot, Vitalii. That was impressively meaningful dialog. We’ve got a lot of insights today. Hope we are not the only ones who enjoyed it.
On a Regulative Note
To continue the regulation topic, another part of the concern is here. It hides in the fact that different governments and authorities have already issued or are preparing regulations to ensure the safe usage of AI technology as a whole and its different elements.
For instance, the European Parliament has already agreed to its negotiating position on the future EU AI Act.
The law-to-be categorizes AI applications into three risk levels. It will ban applications with unacceptable risks, like social scoring systems, imposes specific legal requirements on high-risk applications (such as CV-scanning tools for job applicants), and leaves applications not falling into the banned or high-risk categories largely unregulated.
The AI Act can become a standard for determining AI’s positive or negative effects worldwide. Its impact is evident as other countries like Brazil are considering similar AI regulations. There’s no final text yet; however, its adoption is expected by the end of 2023.
At the same time, the United States lacks a comprehensive framework for AI regulation similar to the EU AI Act. While no significant federal legislation or state laws explicitly target AI, certain state privacy laws may apply to AI systems handling specific categories of personal data.
The most developed and recognized area of law related to AI’s Big Data aspects in the US is the set of federal and state privacy laws governing personal data collection, usage, and safeguarding. Recent attention has been on the CCPA/CPRA in California, and state laws in Colorado, Connecticut, Iowa, and Virginia, which offer varying degrees of protection against automated decision-making. Although the proposed American Data Privacy and Protection Act (ADPPA) made progress in 2022 but didn’t pass, there is uncertainty about the possibility of a federal consumer data privacy law in 2023.
However, according to a verified source, US legislative authorities are very initiative about seeking control over AI systems.
- The National Institute of Standards and Technology (NIST) released the Artificial Intelligence Risk Management Framework (RMF) as a voluntary, non-sector-specific guide to aid technology companies in managing the risks associated with AI systems. The RMF aims to promote trustworthy and responsible development and usage of AI systems, offering valuable insights into future AI regulations. Critical aspects of the RMF include recognizing the potential harm AI systems can cause due to objectivity and high functionality assumptions and defining trustworthiness with seven specific characteristics, such as safety, resiliency, explainability, privacy-enhancing fairness, accountability, and reliability.
- Companies seeking to employ AI technologies for healthcare-related decision-making should be aware that the Food and Drug Administration (FDA) plans to regulate numerous AI-powered clinical decision-support tools as medical devices. You can find further details on these regulations here.
- Finally, the Federal Trade Commission (FTC) has revealed its intention to strengthen its scrutiny of companies employing AI by releasing a series of articles cautioning businesses against engaging in speculative automated practices.
And there’s more yet to come. So all we can do is be ready now to avoid undesirable consequences in the future.
I would like to add that if you are building something similar or have your own ideas, let us know, and we’ll discuss it!


